どんなもの?
ユーザーごとの好みや履歴にリアルタイムで適応する personalized agent framework。
先行研究と比べてどこがすごい?
figure 1 が一番わかりやすくまとまっている。
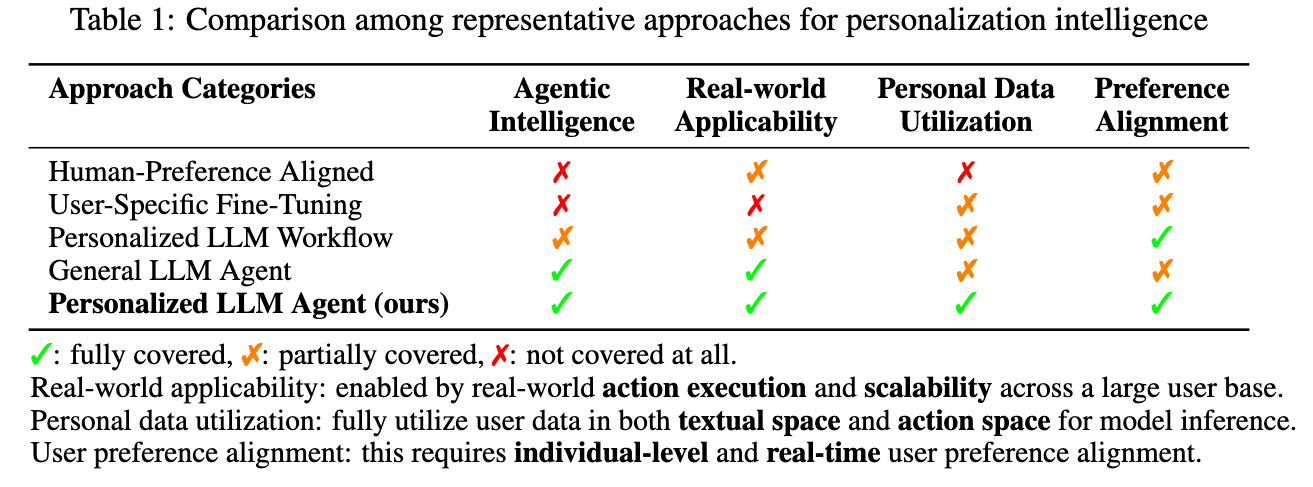
実務的な嬉しさは、
- モデルの重みを更新しなくても良い。
- 出力を個別化できる。
- 実装が比較的単純。
技術や手法のキモは?
Test-Time User Preference Alignment を導入。
要するに、
- 質問をエージェントに入力
- エージェントの回答と実際の回答を比較し、どのように改善するべきかフィードバックを生成
- フィードバックをもとにペルソナを更新
どうやって有効だと検証した?
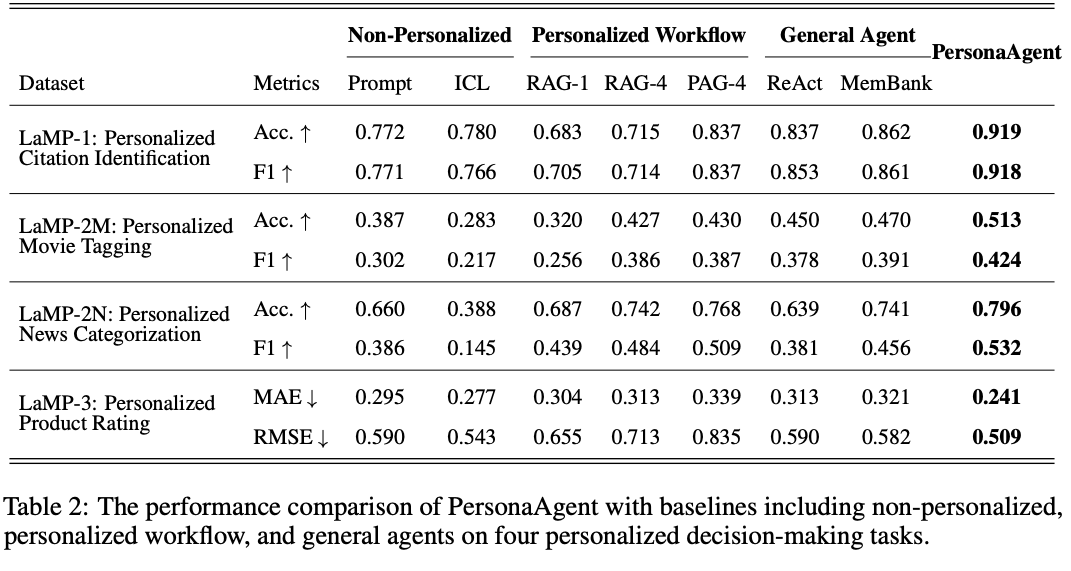
LAMP-1,2,3 にて他の手法よりも優れた精度を記録。
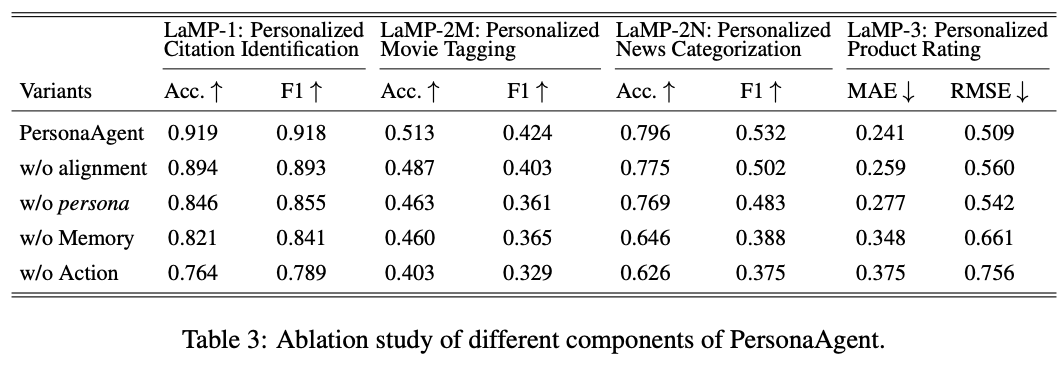
Ablation Study にて各パーツが全て重要であることを主張。なかでも Action がかなり重要そう?
議論は?
プライバシーリスクあり。学習によって得られたペルソナはテキストデータで保持されるので、それが流出するとかなり大変そう(感覚としては検索履歴を覗かれるのに近いので、、、)。
次に読むべき論文は?
- 論文で使われていた LaMP について確認する。
- 4.3 で「ドメインに特化した手法は柔軟性を欠いている」と述べていたが、ドメインに特化した個別化エージェント作成の方法も知っておいた方が良さそう。
感想
有用そうだが、他の論文と比較して LaMP の精度がかなり高いのが気になる。Ours model だけが高いのではなく、RAG などの従来手法も高い。回答させるときのプロンプトも気になる。
また、LaMPの 5,6,7 のタスクの精度を検証していないのも気になる。「その人らしい選択」は実現できても、「その人らしい出力」はもしかして難しい?だとすれば、「その人らしい出力」を実現させるためのパーツを追加する必要がありそう。